
Hoe slim is AI nou eigenlijk?
Een verrassende verkenning.
De ontwikkelingen op gebied van AI gaan sneller dan je bij kunt houden en AI wordt in razend tempo breder en laagdrempeliger toegankelijk gemaakt voor iedereen. Hoogste tijd dus om je been bij te trekken en je te verdiepen in wat AI is, wat AI kan en vooral hoe het jou kan helpen.
In de komende periode zullen we een aantal artikelen over AI publiceren, dus hou de berichten van ITicon in de gaten.
In deze eerste verkenning gaan we aan de slag met drie bekende AI chatbots; Bing Copilot, ChatGPT3.5 en Google Gemini (voorheen Bard). Hier een kleine opsomming van hun kenmerken:
- ChatGPT( versie 3.5): Gratis toegankelijk via openai.com. Versie 4 toegankelijk via betaald abonnement.
- Bing Copilot: Gratis toegankelijk via de Microsoft Edge browser. Maakt onder water gebruik van GPT-4.
- Google Gemini: Gratis toegankelijk via gemini.google.com. Maakt gebruik van een eigen AI-model van Google.
Door Bing Copilot en ChatGPT versie 3.5 te testen vergelijken we dus eigenlijk GPT-3.5 en GPT-4.
De verkenning
Hoe vliegen we dit aan?
In de titel van dit artikel stellen we de vraag “Hoe slim is AI?” Maar wat is de definitie van slim? Die vraag kan een heel op zichzelf staand artikel zijn. De hierboven genoemde chatbots zijn alle drie “Large Language Models”. Tools die gevoed zijn met onvoorstelbare hoeveelheden data en die op basis van die data een output genereren als antwoord op de input die een gebruiker invoert.
De chatbots hebben dus ontzettend veel kennis (data) om uit te putten. Maar slim zijn, de mate van intelligentie, gaat er veel meer om dat je kunt redeneren, verbanden kunt leggen, problemen kunt doorgronden en oplossen.
Door een aantal problemen voor te leggen aan de chatbots kunnen we gaan ontdekken in hoeverre de chatbots op dit moment om kunnen gaan met prompts waarin gevraagd wordt om een probleem te analyseren en met een oplossing te komen. Hiervoor kunnen we uitstekend een aantal soorten opgaves gebruiken die in IQ-tests worden gebruikt.
Soort vragen
Niet elk type opgave uit een IQ-test is geschikt om als test te gebruiken. Naast de eerdergenoemde grote hoeveelheid kennis (data) heeft een chatbot, vergeleken met een mens, natuurlijk ook een enorme rekenkracht. Opgaves uit een IQ-test die taalkennis testen (bijvoorbeeld vragen over synoniemen of antoniemen) of opgaves die de vaardigheid in (hoofd)rekenen testen worden door de chatbots, conform verwachting, tijdens onze verkenning allemaal foutloos beantwoord.
Interessanter zijn de opgaves waarin de chatbots moeten gaan redeneren en verbanden moeten leggen. Twee soorten opgaves zijn daarvoor uitermate geschikt en gebruiken we in onze verkenning: Het aanvullen van complexe cijferreeksen en het oplossen van complexe redactiesommen. Om een indruk te krijgen van het soort opgaves dat we gebruikten, hier een voorbeeld:

Dit is een voorbeeld van een opgave die wiskundig niet erg complex is, maar waar begrijpend lezen een belangrijke rol speelt om de informatie uit de tekst te halen
Onze constateringen
Na uitvoering van de verkenning hebben we een aantal interessante constateringen. De vier belangrijkste delen we hier:
1e constatering: Een exacte vergelijking is onmogelijk.
De bedoeling van deze verkenning was om een exacte vergelijking te maken van het oplossend vermogen van de verschillende chatbots. Maar het werd al snel duidelijk dat een exacte vergelijking niet te maken is. Waarom niet? Dat is gelijk misschien wel de meest interessante constatering van deze verkenning: Dezelfde opgave meerdere keren invoeren bij dezelfde chatbot leidt steeds tot andere redeneringen, tot een ander type uitleg en regelmatig zelfs tot andere eindantwoorden.
Tot nu toe kon je er bij computers vanuit gaan dat dezelfde input altijd leidde tot dezelfde output. Dat is bij chatbots echt niet meer het geval. De ene keer is de uitleg die gegeven wordt veel wiskundiger en een volgende keer veel meer verhalend. De ene keer is de uitleg correct en de volgende keer slaat hij de plank helemaal mis. Kortom: per keer verschilt het hoe “slim” de chatbot is in zijn antwoord. Hieronder zie je twee pogingen van Bing Copilot om de hierboven beschreven opgave op te lossen. In beide gevallen is de opgave ingevoerd in een nieuw opgestarte instantie van de chatbot. Maar alleen bij de eerste poging komt Bing Copilot tot het juiste antwoord.
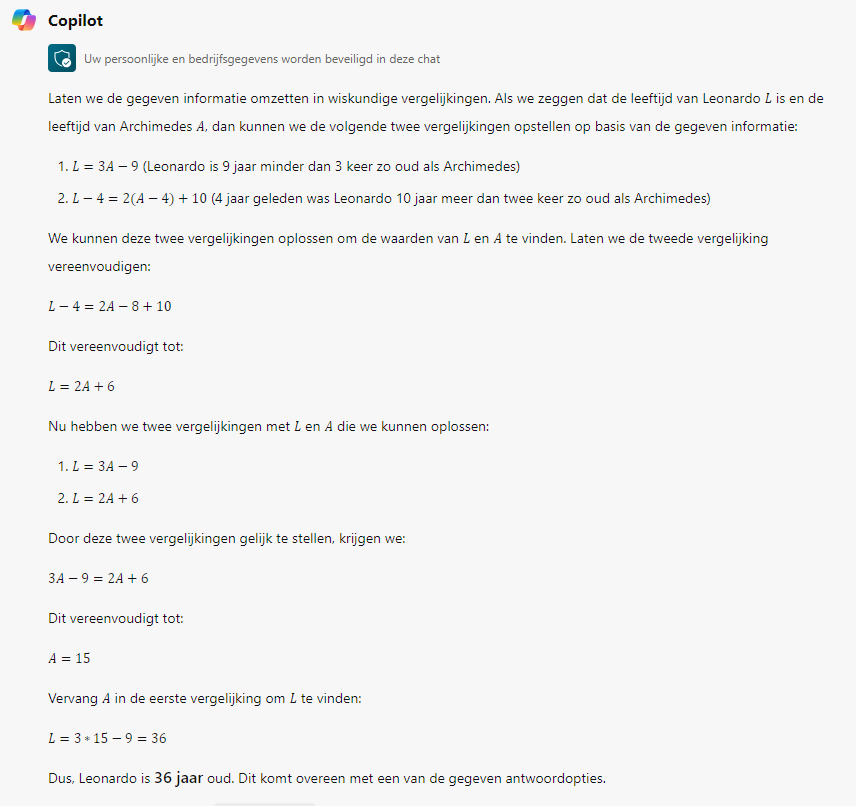
Figuur 1: eerste poging Bing Copilot
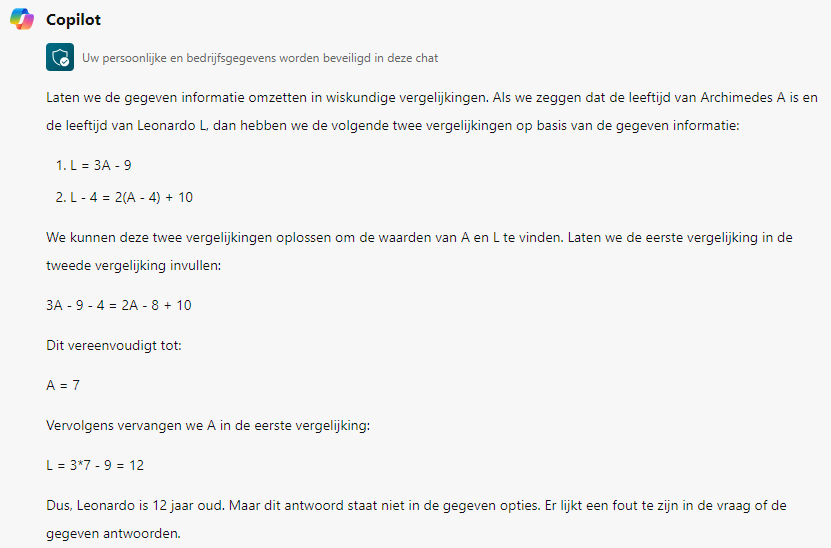
Figuur 2: tweede poging Bing Copilot
Bij deze twee pogingen is de output van Bing Copilot qua toon en aanpak nog erg vergelijkbaar. Het is opvallend om te zien dat in beide gevallen de informatie uit de tekst juist wordt begrepen en correct wordt omgezet in formules. Maar bij de tweede poging gaat Bing Copilot in de fout met het vereenvoudigen van de vergelijkingen. Terwijl dat vereenvoudigen van de vergelijkingen juist een stukje standaard rekenwerk is.
2e constatering: Bij vlagen maken de chatbots bijzonder domme fouten.
Hierboven is natuurlijk al een voorbeeld te zien van een rekenfout. Maar er zijn nog veel opvallendere en “dommere” fouten voorbij gekomen. Het lijkt erop dat de chatbots regelmatig hun eigen werkelijkheid gaan creëren als ze vastlopen bij het oplossen van een opdracht. Vooral bij het oplossen van de cijferreeksen valt op dat de chatbots fouten gaan maken en onjuistheden beweren, als ze moeite hebben met het ontdekken van een patroon. Zo wordt regelmatig een eigen logica gecreëerd die helemaal niet in de reeks aanwezig is. Voorbeelden van fouten die gemaakt werden: “20 * 3 = 33” en “36 gedeeld door 5.5 is 9”.


Figuur 3: Voorbeeld van een rekenfout van Google Gemini.
3e constatering: Er zijn per chatbot wel trends te ontdekken.
De vergelijking van de chatbots is lastig, omdat de output en het antwoord per chatbot niet altijd consequent juist of onjuist wordt gegeven. Maar door grote aantallen opgaves meerdere keren door de drie chatbots op te laten lossen, is er wel een trend te zien. Bing Copilot is het sterkst bij het oplossen van de complexe redactiesommen, waar Google Gemini juist bij de complexe cijferreeksen met kop en schouders boven de andere 2 chatbots uitsteekt.
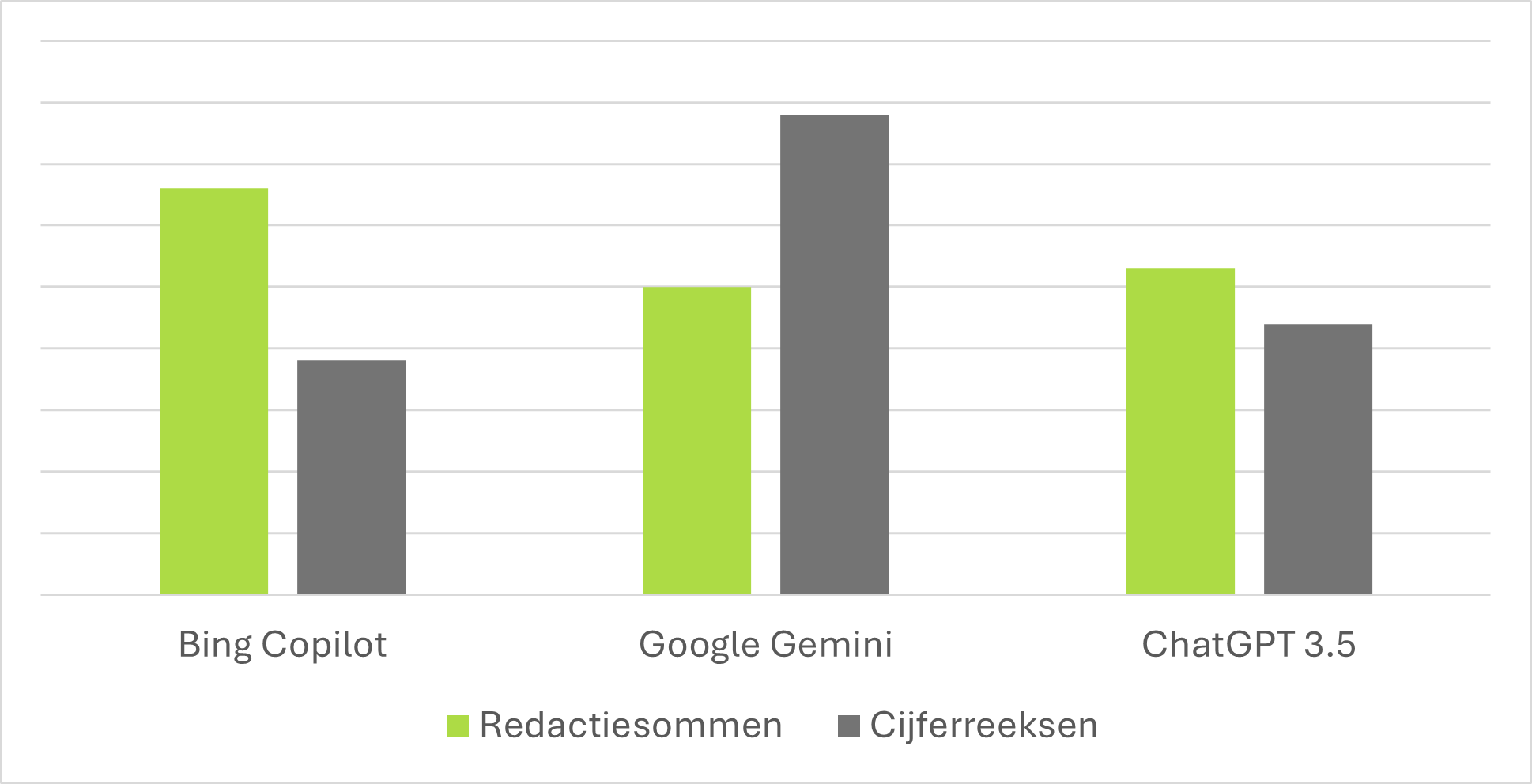
Figuur 4: Trend oplossend vermogen
4e constatering: Gebruiksvriendelijkheid verschilt per chatbot.
Wat tijdens de verkenning opvalt is dat de antwoordsnelheid van Google Gemini en ChatGPT vele malen beter dan die van Bing Copilot. Bij Bing Copilot moet je regelmatig lang wachten op het antwoord en valt de verbinding soms weg. Google Gemini komt vrijwel direct met een antwoord. Dit maakt Google Gemini in de praktijk fijner in het gebruik, omdat de samenwerking met de chatbot veel vloeiender gaat.
Conclusie
Voor alle drie de chatbots geldt: Het oplossend vermogen, de gegeven uitleg en de resultaten zijn veelal ronduit indrukwekkend. Hoewel de chatbots taalmodellen zijn, blijken ze behoorlijk goed te kunnen puzzelen en redeneren. Maar blijf alert! Behandel de output van de chatbot altijd als een inspirerend startpunt en controleer deze altijd op juistheid. Want ook in de simpele redeneringen kunnen de chatbots soms onverwacht “domme” fouten maken. Overschat de intelligentie van de chatbots dus niet want, zoals Google Gemini regelmatig zelf zegt: “Ik ben slechts een taalmodel.”

Geschreven door Michiel de Kuijper – ITicon B.V.
Groei door kennisdeling | Samen meer waarde
#AIartikel #ITiconArtikelen #ChatGPT #GoogleGemini #CoPilot